Общий поиск: проект с открытым исходным кодом, возвращающий PageRank

За последние несколько лет Google постепенно сокращал объем данных, доступных для специалистов по SEO. Сначала это было данные ключевых слов , затем Оценка PageRank , Теперь есть определенный объем поиска из AdWords (если вы не тратите немного мула). Вы можете прочитать больше об этом в Отличная статья Расс Джонс это детализирует влияние исследований его компании и понимание данных о потоках кликов для устранения неоднозначности объема.
Одна вещь, в которую мы действительно вовлеклись в последнее время, это Общие данные сканирования , В нашей отрасли есть несколько команд, которые используют эти данные в течение некоторого времени, поэтому я немного опоздал к игре. Common Crawl data - это проект с открытым исходным кодом, который регулярно очищает весь интернет. К счастью, Amazon, будучи великой компанией, хранить данные сделать его доступным для многих без высоких затрат на хранение.
В дополнение к данным Common Crawl, существует некоммерческая организация под названием Common Search чья миссия заключается в создании альтернативного открытого исходного кода и прозрачной поисковой системы - во многих отношениях противоположности Google. Это пробудило во мне интерес, потому что это означает, что мы все можем играть, настраивать и манипулировать сигналами, чтобы узнать, как работают поисковые системы без огромных затрат времени, начиная с нуля.
Общие данные поиска
В настоящее время Common Search использует следующие источники данных для расчета рейтинга в поисковых системах (это взято непосредственно из их Веб-сайт ):
- Обыкновенный обход : Крупнейшее открытое хранилище данных веб-сканирования. В настоящее время это наш уникальный источник необработанных данных страницы.
- викиданные Свободная, связанная база данных, которая служит центральным хранилищем для структурированных данных многих проектов Викимедиа, таких как Википедия, Викивояж и Викитека.
- UT1 Черный список Этот черный список, поддерживаемый Фабрисом Прижент из Капитолия Университета Тулузы 1, разделяет домены и URL-адреса на несколько категорий, включая «взрослые» и «фишинговые».
- DMOZ Также известный как Open Directory Project, это самый старый и самый большой веб-каталог, который еще существует. Хотя его данные не так надежны, как это было в прошлом, мы все равно используем их в качестве источника сигналов и метаданных.
- Графики гиперссылок общих данных в Интернете : Графики всех гиперссылок из архива Common Crawl 2012 года. В настоящее время мы используем его файл Harmonic Centrality в качестве временного сигнала ранжирования доменов. Мы планируем провести собственный анализ веб-графа в ближайшем будущем.
- Alexa топ 1M сайтов : Alexa ранжирует сайты на основе совокупной оценки просмотров страниц и уникальных пользователей сайта. Это, как известно, демографически предвзято. Мы используем его как временный сигнал ранжирования доменов.
Рейтинг общего поиска
В дополнение к этим источникам данных при исследовании кода он также использует длину URL, длину пути и домен PageRank в качестве сигналов ранжирования в своем алгоритме. И вот, с июля у Common Search появились собственные данные о уровень хоста PageRank и мы все пропустили это.
Я скоро доберусь до PageRank (PR), но интересно рассмотреть код Common Crawl, особенно часть ranker.py, расположенную Вот потому что вы действительно можете сесть на место водителя, настроив вес сигналов, которые он использует для ранжирования страниц:
signal_weights = {"url_total_length": 0.01, "url_path_length": 0.01, "url_subdomain": 0.1, "alexa_top1m": 5, "wikidata_url": 3, "dmoz_domain": 1, "dmoz_url": 1, "webdatacommons": 1, webdatcommons , "commonsearch_host_pagerank": 1}Также следует отметить, что Common Search использует BM25 как мера сходства ключевого слова с телом документа и метаданными. BM25 является лучшим показателем, чем TF-IDF, поскольку он учитывает длину документа, а это означает, что документ из 200 слов, в котором содержится ключевое слово пять раз, вероятно, более релевантен, чем документ из 1500 слов, в котором используется такое же количество раз.
Также стоит сказать, что количество сигналов здесь очень элементарно и, очевидно, отсутствует множество усовершенствований (и данных), которые Google включил в свой алгоритм ранжирования поиска. Одна из ключевых вещей, над которой мы работаем, - это использовать данные, доступные в Common Crawl, и инфраструктуру Common Search для поиска тематического вектора для контента, релевантного на основе семантики, а не только соответствия ключевых слов.
На PageRank
На странице Вот Вы можете найти ссылки на PageRank уровня хоста для Общего сканирования в июне 2016 года. Я использую тот под названием pagerank-top1m.txt.gz (топ 1 миллион) потому что другой файл 3 ГБ и более 112 миллионов доменов. Даже в R у меня не хватает машины, чтобы загрузить ее без выключения.
После загрузки вам нужно будет перенести файл в ваш рабочий каталог в R. Данные PageRank из Common Search не нормализованы, а также не в чистом формате 0-10, в котором мы все привыкли его видеть. Common Search использует «Max (0, min (1, float (rank) / 244660.58))» - в основном, рейтинг домена, деленный на рейтинг Facebook - как метод преобразования данных в распределение между 0 и 1. Но это оставляет определенные пробелы в том, что это оставило бы PageRank Linkedin'а в 1,4 при масштабировании на 10.
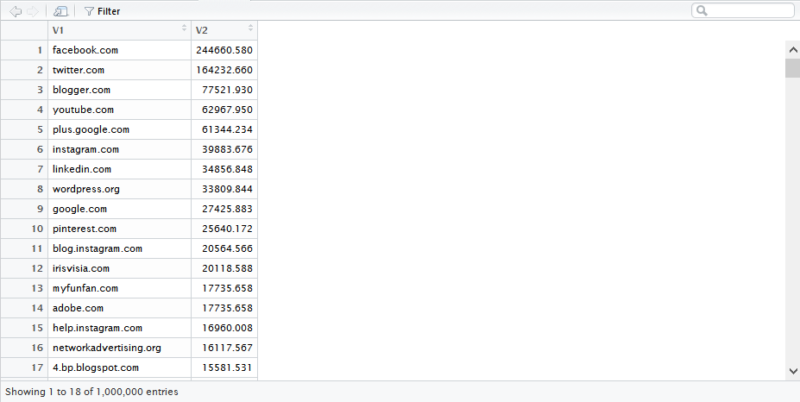
Следующий код загрузит набор данных и добавит столбец PR с лучшим приближенным PR:
# Захватить данные df <- read.csv ("pagerank-top1m.txt", header = F, sep = "") #Log Нормализовать logNorm <- function (x) {#Normalize x <- (x-min (x) )) / (max (x) -min (x)) 10 / (1 - (log10 (x) *. 25))} # Добавить столбец с именем PR к набору данных df $ pr <- (round (logNorm (df) $ V2), цифры = 0))
Нам пришлось немного поиграться с числами, чтобы приблизить их (для нескольких образцов доменов, для которых я запомнил PR) к старому Google PR. Ниже приведены несколько примеров результатов PageRank:
- en.wikipedia.org (8)
- searchengineland.com (6)
- consultwebs.com (5)
- youtube.com (9)
- moz.com (6)
Вот график из 100 000 случайных выборок. Рассчитанная оценка PageRank идет вдоль оси Y, а исходная оценка общего поиска - вдоль оси X.

Чтобы получить свои собственные результаты, вы можете запустить следующую команду в R (просто подставьте свой собственный домен):
DF [DF $ V1 == "searchengineland.com", с ( 'пр')]
Имейте в виду, что этот набор данных содержит только один миллион доменов по PageRank, поэтому из 112 миллионов доменов, проиндексированных Common Search, вполне вероятно, что ваш сайт может отсутствовать, если у него нет довольно хорошего профиля ссылок. Кроме того, этот показатель не содержит указания на вредоносность ссылок, а лишь приблизительную оценку популярности вашего сайта по отношению к ссылкам.
Общий поиск - отличный инструмент и отличная основа. Я с нетерпением жду возможности больше поучаствовать в сообществе и, надеюсь, научиться лучше понимать основные моменты поисковых систем, работая над ним. С помощью R и небольшого кода вы можете быстро проверить PR на миллион доменов за считанные секунды. Надеюсь тебе понравилось!
Мнения, выраженные в этой статье, принадлежат автору гостя и не обязательно относятся к Search Engine Land. Штатные авторы перечислены Вот ,